テキストの類似度に基づく類似スコアリング
引き続きエクセルの配列機能を応用したツールを開発していまして、なかなか良さそうな分析ツールができたので紹介します。
このツールの開発を始めたきっかけなんですが昨晩もChatGPTのCode Interpreterと特許情報分析について問答してまして、既存のマップツールでできる統計分析的なことを掘り下げても劣化コピー的な結果しか出せないので付加価値は低いと思い、テキスト分析について主に議論をしていました。
そうしたところ、文章同士の類似度を評価するコサイン類似度という評価手法を教えてもらいました。Code InterpreterでできることなのでPythonの環境を整えれば同じような分析はできそうです。しかし、分析する母集団のリストを作るたびに処理するのも面倒に思い、エクセルでなんとか実装できないかコサイン類似度についてネットで調べてみました。
しかし小難しい数式が示されているものばかりでエクセルの分析に取り込めそうとは思えませんでした。うーん、どうしたものか。
ところで、Google Patentsにも類似特許の機能がありますけど、アレどうやって関連度を算出してるんですかね?便利なんですよね。特定の特許に対して調査対象にする母集団の複数の特許のそれぞれについて類似度を自分で簡単にスコアリングできたらスクリーニングも効率化できそうでいいなと思いました。
ということで何とかなるかもしれないしチャレンジしてみようと検討したところ、エクセルの配列機能をフルに活用し手持ちの技術を組み合わせることでなんとか意図する機能が実装できました。以前から度々紹介しているLambda関数やらTEXTSPLIT関数やらMicrosoft365の機能をフルに使って作っています。
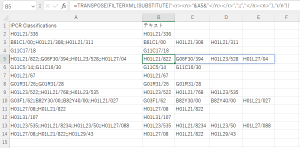
このツールでは、英語の要約を対象に、基準にする特許の要約における語を使って他の特許を評価します。そして特徴語や一般語に適宜の重み付けをし類似スコア(類似度)を算出することで類似度のスコアリングをしています。この例でも、引き続きTSMC社の最近の1000件のファイルで試作していますが、D列は参考用の機械翻訳です。

画像の例では、3D ICに関連する特許(US2023/0170328A1)を基準に設定すると、技術的にみてそれなりに近そうな特許が抽出できているようです。
例えば、5件目のUS11658164B2ではiPhoneなどのプロセッサに使われているInFOパッケージ技術(APとメモリを積層する3D IC技術)に関する特許が3番目とハイスコアになるようにスコアリングできていて、実用可能なレベルと感じました。重み付けをもっとしっかり計算すれば精度は上げられるのでしょうが処理が重くなったり件数が増えたら動かなくなっては本末転倒なので、開発はこの辺で止めておこうかと思います。
このツールでは特定の出願を基準にスコアリングしていますが、ちょっと工夫すれば任意の会社の出願ポートフォリオから基準を作り、特定の母集団をスコアリングするツールにすることもできそうです。それから、ここでは具体的な内容は説明しませんが、特許分類を利用したスコアリングツールも実は開発済みで実用していたりします。
以上の手法を含め弊所では様々な特許情報分析の手法を用意しており、クライアントの要望に沿った分析手法の開発も行っています。
また、このような分析手法に関するセミナーや分析プロジェクトについても対応可能ですので、ご相談などありましたら管理人の特許事務所のページからお知らせください。
よろしくお願いします。