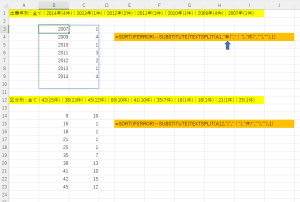
こういうのでいいんだよ、こういうので。
前の記事に引き続い商標情報をChatGPTで確認する話をしたいと思います。前の記事は以下からどうぞ。
商標も意外と分かってるChatGPT | patent & marketing (patent-and-marketing.com)
前の記事で試したようにCode Interpreterでグラフ化することはできるのですが日本語の使用が制限されていたり細かな調整が難しいなどの問題があるため、いっそのことデータをグラフ化しやすい形に加工してもらうほうがよいと思ったので試してみました。
データは引き続きツイッター社の出願です。J-PlatPatの検索結果にテキスト形式に出力されている出願年別と区分別の件数を、エクセルでグラフにしやすい表形式にするようにお願いしてみます。
区分についても、数字だけ分かってもそれが何か分かは分かりにくいので説明もついでに入れてもらうよう依頼します。
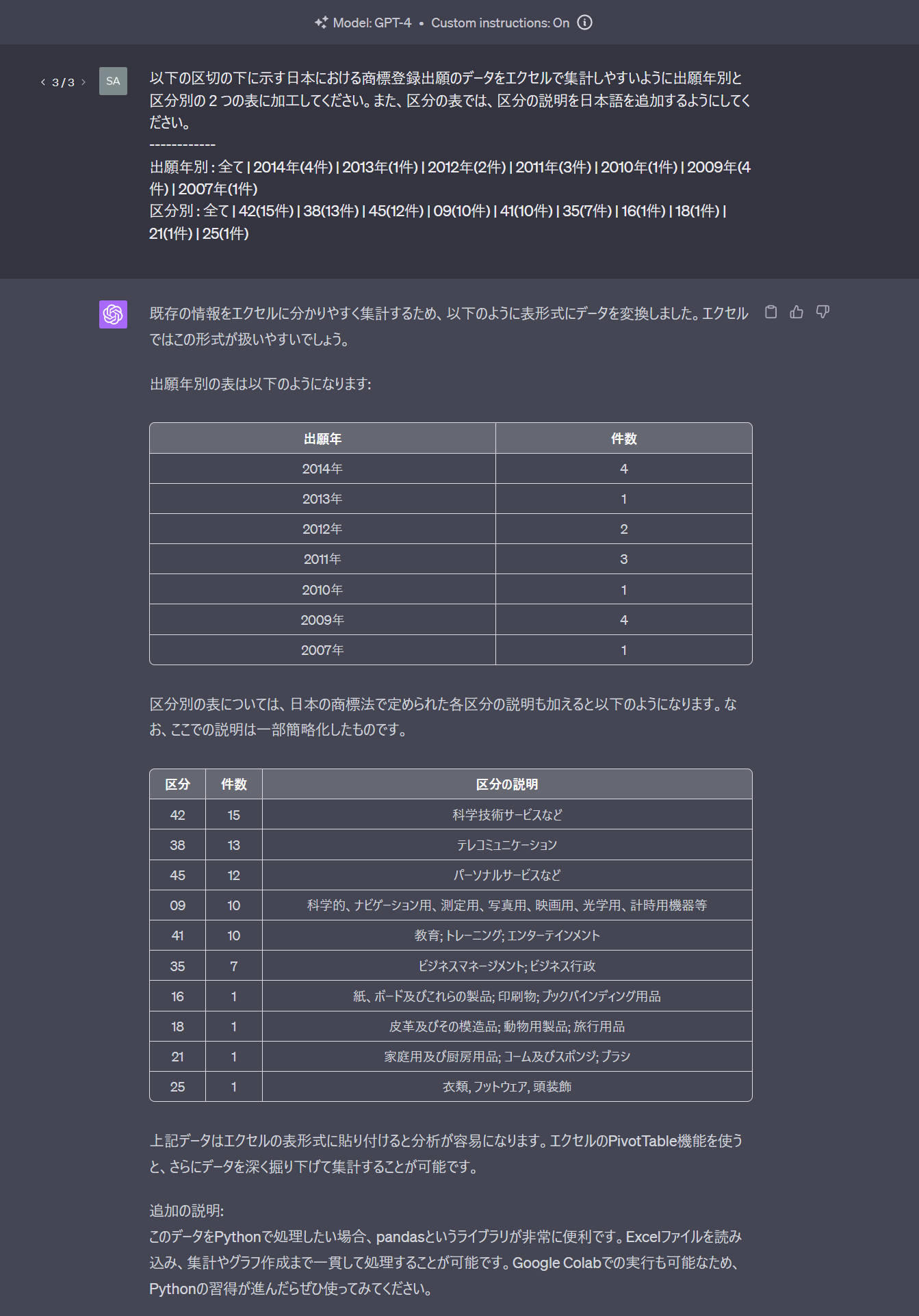
無難に処理してくれますね。Code Interpreterでグラフ化してもらうより正直言ってこっちのほうがいい気がします。
データとして素直に使いやすいですし、説明も付いてるのでこの情報だけで出願分野を把握できます。
そんなわけで、エクセルでグラフ化というか条件付き書式のデータバー付きの表にします。
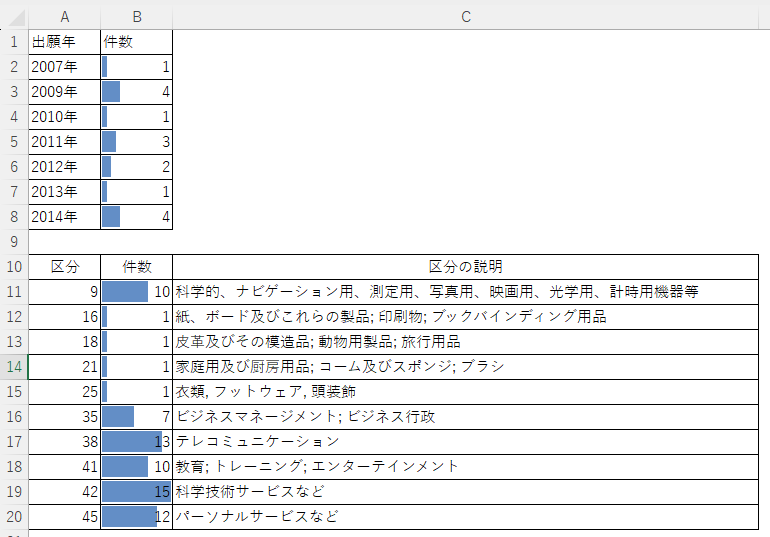
「こういうのでいいんだよ、こういうので。」と思いました。こういう細かくめんどうな作業はChatGPTにどんどん投げていきたいですね。
以上の画像で記事を書き始めたのですが、もう少しプロンプトを工夫したほうが便利かなと思ったのでプロンプトの記載を少し追加しました。
並び順を変えたり、欠損値を補ったり、説明を補ったりするように変えています。
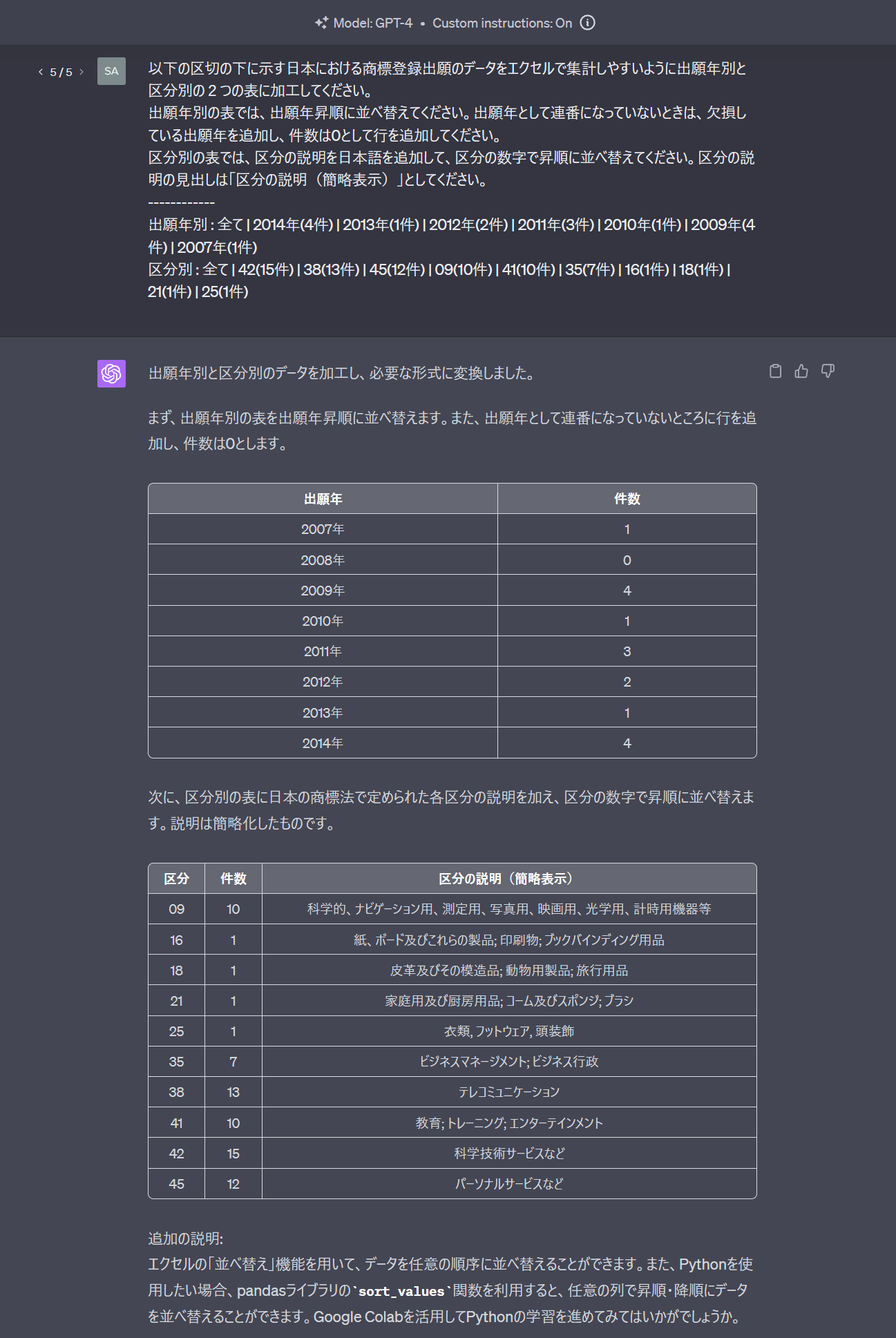
上で示したようにエクセルにコピペしてグラフ化するのもいいんですが、正直言ってこれだけでもいいかなという気がします。
欠損値の補完もエクセルで処理しようとすると意外と面倒なので助かります。
もちろん、こういう処理をよく行う場合にはエクセルの数式などで作り込んでもいいのですが、定常的でない作業として行う場合にはChatGPTに任せた方が楽でよさそうですね。
折角なので修正後のプロンプトを置いておきます。よかったら使ってみてください。
区切文字の下に示す日本における商標登録出願のデータをエクセルで集計しやすいように出願年別と区分別の2つの表に加工してください。
出願年別の表では、出願年昇順に並べ替えてください。出願年が連番になっていないときは、欠損している出願年を行として追加し、件数は0としてください。
区分別の表では、区分の説明を日本語で追加して、区分の数字で昇順に並べ替えてください。区分の説明の見出しは「区分の説明(簡略表示)」としてください。
------------好きなように加工して使って貰えればと思います。それから、J-PlatPatでは特許や意匠の検索でも似たような簡易分析結果を出力できるので、区分のところをIPCなどに読み替えてもらうようにプロンプトを変えてもいいかもしれませんね。
今回は以上です。