J-PlatPatからダウンロードしたCSVから自動集計するツールを開発した話
今回はタイトルのツールを開発した話を紹介します。
作成経緯
J-PlatPatでは、出願日、発明の名称、出願人名、FI(ファイルインデックス)などの情報をCSV方式で一括してダウンロードできます。
このCSVを使ってエクセルで何か面白いツールができないか考えていて最初に思いついたのはダッシュボードツールでした。
具体的には、CSVで取得できる項目について自動集計して5個~10個程度のグラフや表を一括して閲覧できるようにすることで、ダウンロードしたCSVの母集団ではいつごろどんな出願人がどんな技術に出願していてそれらがどのような権利状態になっているかを、簡単に俯瞰的に確認できるようにするのはどうかと考えました。
また、集計する場合には、例えば出願された年ごとに出願件数を単純にランキングするような集計だけでなく、出願年と出願人とを軸にとりどの出願人がいつ出願しているかとか、出願人と特許分類とを軸にとりどの出願人がどんな技術について出願しているようないわゆるクロス集計したデータも収録したいと考え、CSVのデータを貼り付けるだけで自動集計できるツールを作ってみることにしました。
初期バージョン
そんなことを考えながら最初に作ったツールがこちら↓
この後説明する最終形態からするとシンプル!
C列で横軸と縦軸の項目を選択できるようにしてあり、これらを適宜選択することで縦軸と横軸との両方の条件を満たす出願件数を集計します。
このような集計をする場合、縦軸と横軸にデータを手作業などで貼り付け、これらの軸の交差点になる範囲にCOUNTIFS関数を使った数式を必要な行列分だけ貼り付けて計算んさせます。しかし、このような処理もエクセルの初心者では難しく、計算方法を知っていても手間がかかり面倒です。
そこで、このツールでは、まず、CSV貼付用のシートに貼り付けたCSVから各項目の出願件数ランキングを自動集計します。次に、そのランキング表のデータを使いC列での設定に従って縦軸と横軸を自動で設定します。そして、表示された縦軸と横軸との交差したセルに数式を自動的に展開します。これにより、CSVのデータから別途生成した集計用の表に基づいて出願件数をクロス集計させるようにしました。
なお、このツールでは処理する件数が増えても実用上問題ない処理速度を確保するために、1出願ごとの各項目は1つの値だけを読み取る方式にしています。つまり、出願人やFIのような項目では1つの出願に複数付与される場合が多いですが、筆頭FIや筆頭出願人というように最初の1つに絞って集計することにしています。このため、筆頭でない共同出願人や筆頭でない特許分類は分析する対象になりません。このような処理は考え方によっては正確な分析ではないとも言えますが、そのような仕様を知ったうえで使うのであれば問題ないと考えています(もちろん、別の方法を使えば筆頭でない出願人やFIを集計することもできます)。
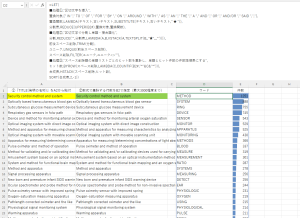
これにより、CSVを貼り付ければ上記のシートのC列での項目を選択するだけで集計ができるようになっています。また、画像は特に表示しませんが出願年などの各項目ごとのランキングも自動で計算しています。また、FIのクラスとサブクラスについては上の画像のように説明文を自動で読み込むようにしました。
そして、このツールの特徴として、筆頭FIや筆頭出願人と同じように、発明の名称も句点や接続句を使って筆頭のものを抜き出して集計しています。このような集計機能は商標DBでもあまり無いように思います。
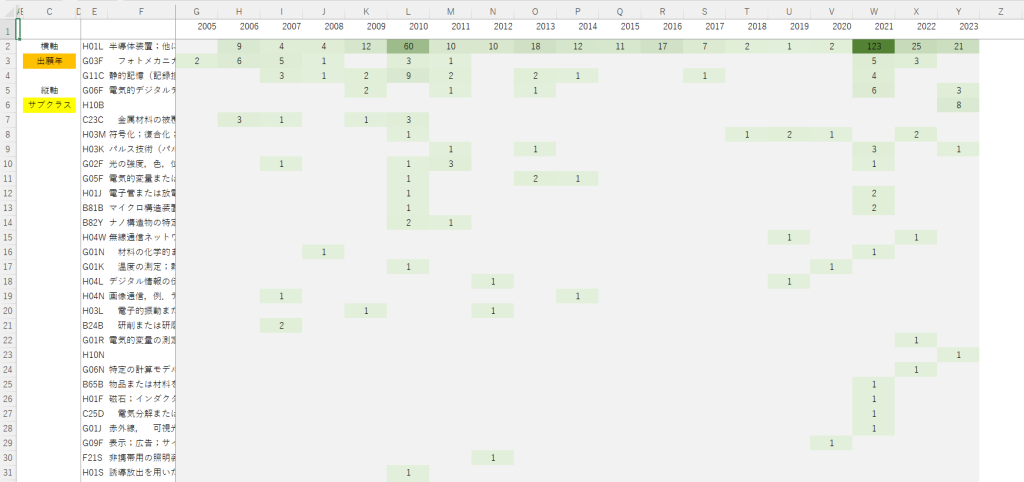
画像の例ではあるゲーム会社の特許を集計していますが、ゲームプログラムやゲーム装置などの発明の名称が付けられた技術がいつごろ出願されたか確認できるようになっています。
ここまで作ったところでこのツールについてなかなか筋がよさそうな印象を受けました。そこで、いくつか改良していくことにしました。
改良バージョン1(軸フィルタの追加)
まずは、縦軸のフィルタを用意しました。この例では「プログラム」を含む発明の名称のみを表示するように設定しています。これにより、「ゲーム装置」のような発明は表示されなくなりました。特許出願において発明のカテゴリを検討することは重要ですが、このような見方をすることで、自社が出願すべきカテゴリを見つけることができ、出願する発明のカテゴリの検討を行うような場合に活用できるのではないかと感じました。

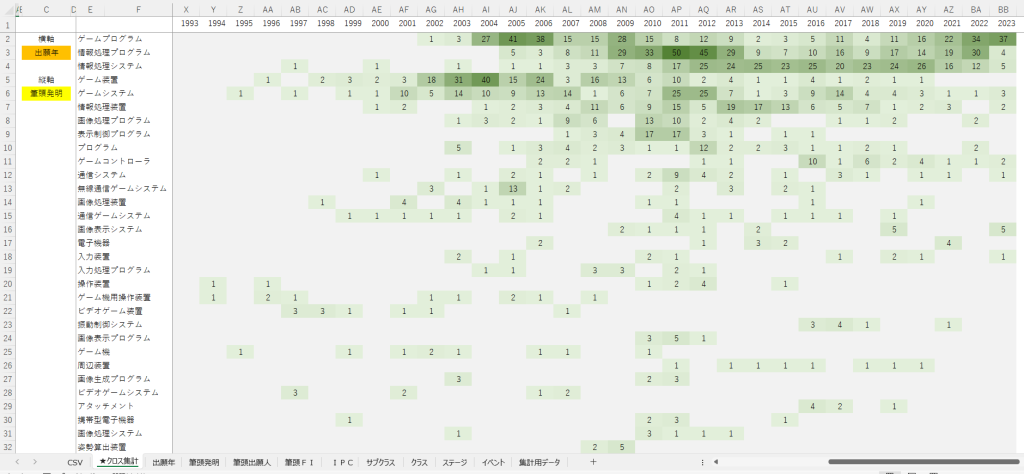
続いて、横軸のフィルタも付けました。この例では、6月のセミナーで題材にする予定のパルスオキシメータについて集計しています。
画像の状態では筆頭出願人と筆頭発明を軸にとることで、主要メーカがどんな名前で出願しているか一目で確認できています。また、酸素濃度を測定するパルスオキシメータの母集団なのに、グルコースの濃度を測定する装置についても含まれていることがわかり、検索式に問題があるのではないかという仮説も得ることができます。

次の画像の例では筆頭FIと筆頭発明を軸にとることで、それぞれの発明について、どんな特許分類が付与されているかを確認できます。
つまり、この発明の調査をするときに採用すべき特許分類を確認することができます。
逆に、特定の特許分類がわかったときに、その分野の発明をさらに調査するために検索式で設定すべきキーワードも確認することができるともいえます。

改良バージョン2(オートフィルタを使ったデータフィルタ)
ここまでのツールでも簡易な分析や調査の支援には使えそうという印象は持ったものの、もう一歩という印象がありました。
というのも、例えば出願1000件文のCSVを貼り付けるとすべてがクロス集計の対象になります。このため、最初に集めてきた母集団(例えば1000件)のなかで特定の出願人(例えば100件)だけに絞って集計をするということができませんでした。
一方で、このツールの作成方針として、基本的に自動で処理が行えることを目的にしているため、集計対象に合わせてデータを減らす手作業は増やしたくありません。また、フレキシブルな絞り込みができるようにエクセルの基本機能であるオートフィルタ機能を使って絞り込みをかけられるようにしたいと考えていました。
そこで、このようなデータフィルタ機能を実現するために調査しましたが、同様の集計をする例は見つかりませんでした。また、SUBTOTAL関数やAGGRIGATE関数などを使うことでオートフィルタの絞り込みに連動させた集計ができそうでしたが、今回のツールではこれらの関数を使った列をただ追加すればよいというはものではなさそうでした。
でも何とかできるのではないかと検討していたところ、この問題を解決するためのヒントをXで教えてもらいました。
そして、このヒントを元に、集計用の表とフィルタ用の表の2段階を踏んで、それらを使って集計するという処理を作成しました。これによりデータのフィルタができるようになりました。
処理方法については本来なら秘密にしておくような内容なのですが、Xでもらったヒントで実現できたというのもあり、今回は処理方法も説明します。
具体的に説明すると、集計用の表では、数式欄で記載しているような、オートフィルタの設定に応じて表示されているセルにのみ数字の連番を付与する数式を付けています、これが表示された行だけを集計の対象にします。
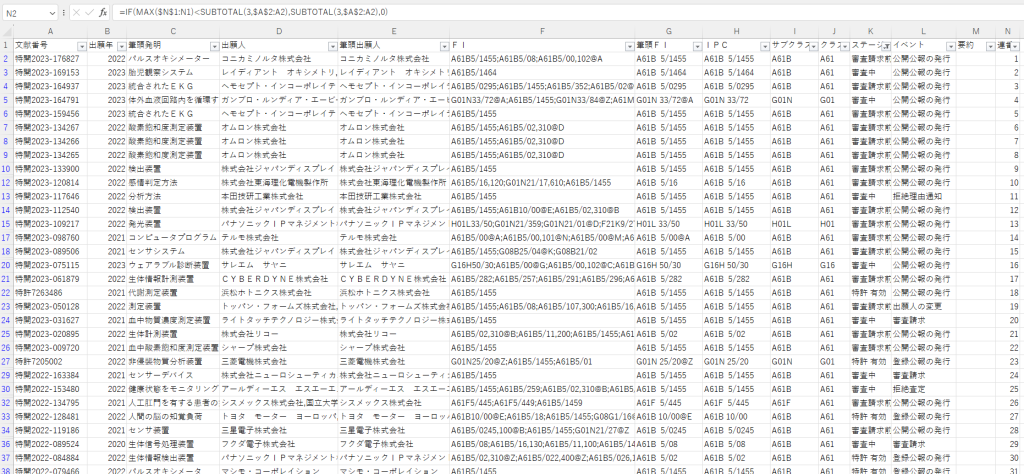
そして、フィルタするシートにおいて、上のシートの連番のデータを使ってフィルタします。
具体的には、下の画像の数式欄で記載しているような数式で読み込むデータを選別して所定の集合に絞り込んだ表を作成します。
そして、このデータを使い個別項目の集計やクロス集計を行うようにしました。
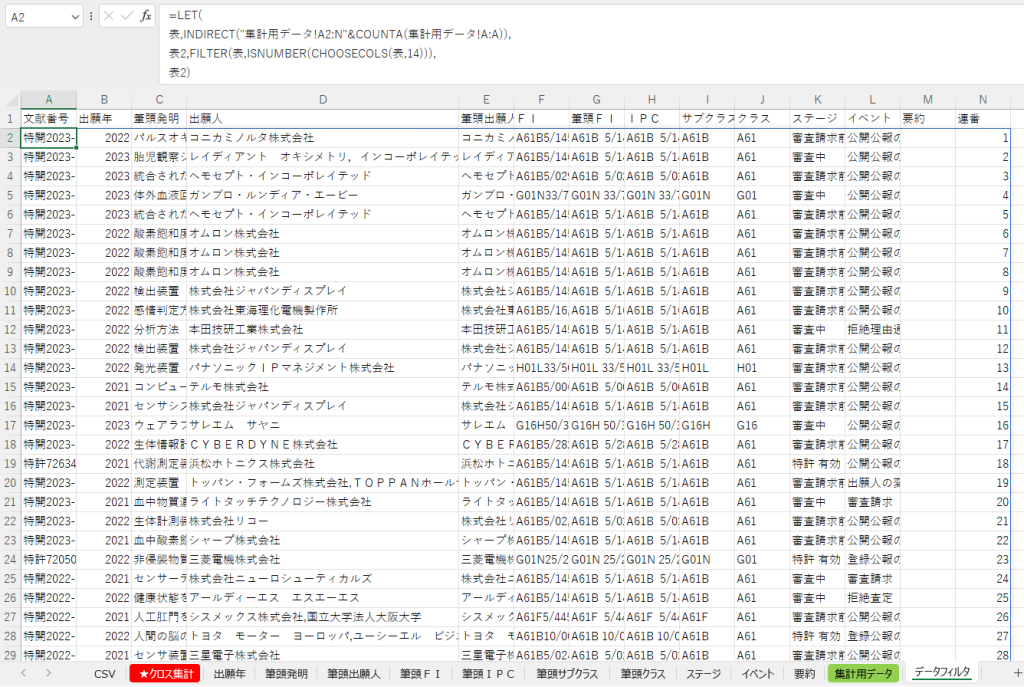
以上のような仕組みにすることで、「集計用データ」シートでオートフィルタを使って任意の項目に絞り込みをすれば、年や出願人やステータスなどを組み合わせたフレキシブルな絞り込みをすることができるようになりました。
例えば、特定の出願人の出願に限って付与されている筆頭FIや出願されている筆頭発明を確認することができるようにできるようになりました。

更に改良を重ね最終的には以下のような形になっています。
このバージョンでは、データフィルタが設定されているか否かの表示を追加しました。

そして、下の画像に示すように、権利の有効無効を確認できる「ステータス」項目を追加してフィルタや集計をより簡単にできるようしたり、「集計用データ」シートにJ-PlatPatへのリンクも設けることで、絞り込んだ集合の出願にアクセスしやすくしました。
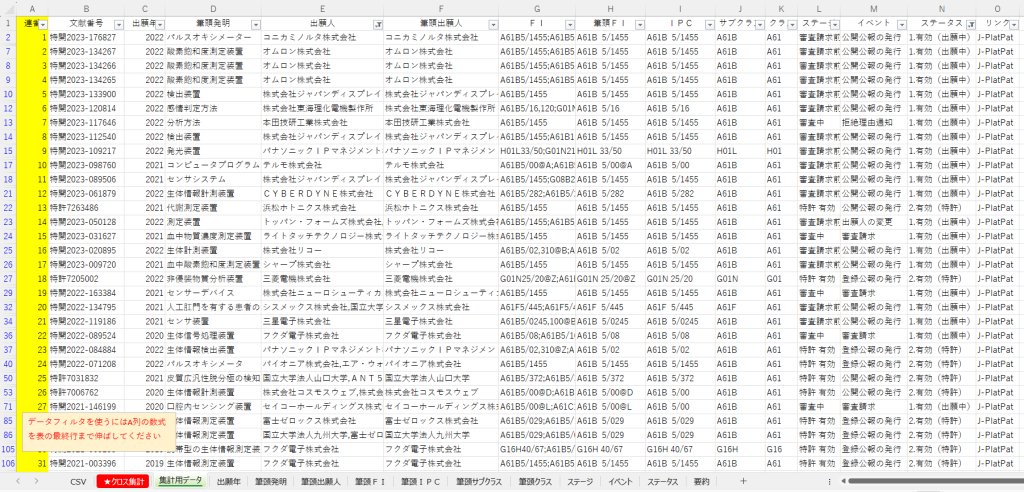
なお、上の画像に黄色く示している連番の列は、残念ながら自動で設定することができなかったため、CSVで貼り付けたデータの行数に合わせてコピペすることにしました。
本当はこのような手作業は発生させたくなかったのですが、ダブルクリックを1回すればいいだけで利用上大きな支障はないとして許容しました。
改良バージョン3(連番の列の削除)
しかし、上記の連番の列を手作業で修正するのは面倒ですしミスも招くおそれがあると考え仕組みの再検討を始めました。
オートフィルタを使う場合に使えるSUBTOTAL関数において、対象とする範囲をスピルで指定してしまうと問題があります。
というのも、このような範囲をSUBTOTAL関数にそのまま設定すると、指定した範囲のそれぞれについて処理がされず、指定した全ての範囲を対象に1つの解が算出されてしまい意図するような処理になってくれません。
Web調査もしましたがよい数式を見つけることができなかったのでダメ元でChatGPTに質問したところ、下の画像のような数式を教えてくれました。
仕組みはよく分かっていませんが、この数式にすることでC2#のようなスピルする範囲を指定しても、対象の行の全てについてフィルタの判別用のデータを算出することができました。
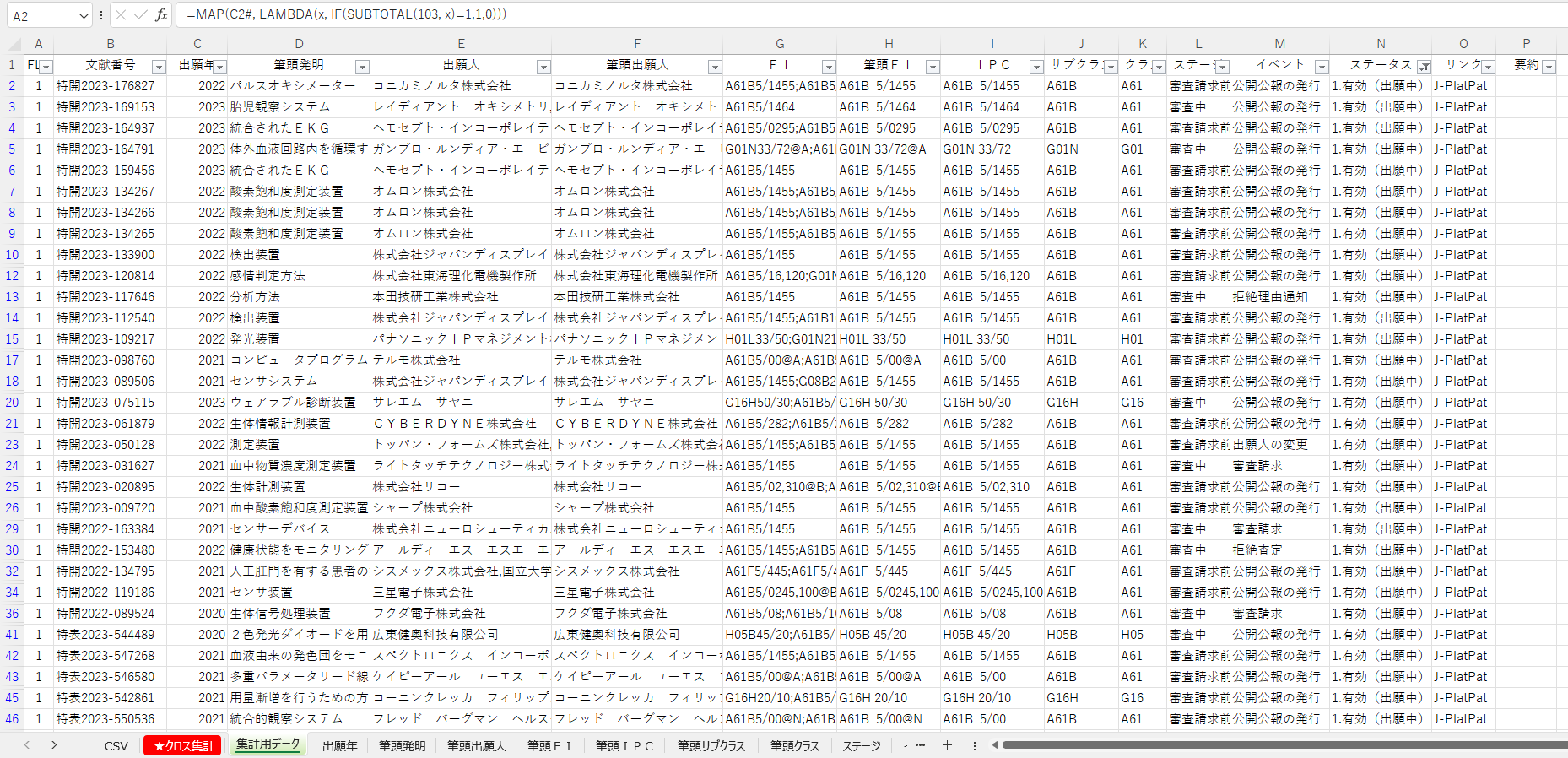
これにより、当初の目論見通り、CSVのシートにJ-PlatPatからダウンロードしたCSVのデータを貼り付けるだけで集計可能なツールができました。
とりあえず無理そうでもなんとか頑張ってみるものですね。MAP関数の存在は知っていましたがこんな使いかたができるとは…!
【4/2追記】ChatGPTに言われるままMAP関数を使っていましたが、そこはBYROW関数でもできるみたいですね。どっちがよいかは分かりませんが、MAP関数は2以上の変数を取ってLAMBDAで処理させることができるらしいのですが、今回は変数は1つなのでBYROW関数に修正しました。
活用法など
作り始めた当初はどんなツールになるかそこまでイメージできていなかったのですが、なかなか役に立ちそうなツールになったと思います。
データの詳細はわからなくていいから母集団に関する情報を簡単にざくっと確認して知財の実務に活用するような用途に役に立つと思います。
このため、例えば、分析ツールは導入をしていないが分析を始めてみたい知財部門や、分析にそこまで時間はかけられないが簡易に分析をして明細書の品質を向上させたい忙しい弁理士などに使ってもらうと効果的かなと感じています。
このツールの今後については、知人に使ってもらい修正点を見つけて修正していきながら、今後の分析セミナーなどで配布できたらなと考えています。
今回の記事は以上です。
本記事などについてお問い合わせなどありましたら右上のリンクから管理人の特許事務所のホームページにアクセスしていただき、お知らせいただければと思います。