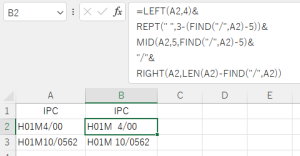
CORREL関数の相関係数に基づく出願人間の類似度の推定
今回の記事では、野崎さんの分析本で紹介されていた関数を使って出願人同士の類似度を推定する方法について紹介します。
野崎さんの「特許情報分析とパテントマップ作成入門第3版」について別にレビュー記事も書きましたが、この本で紹介されていたCORREL関数を実際に使って分析してみました。
CORREL関数は、配列同士を比較して類似している度合いを示す相関係数を算出することができる関数です。
下の画像の例では、GAFAM5社の出願について付与されているCPCの上位1000位をLens.orgで取得してこれらを統合し、統合された特許分類から各社の出願件数を集計することで、5社のそれぞれがどの分類で出願しているか、各分類における各社の件数比較などもできるようなデータを生成しています(G列からL列まで)。
そして、H列からL列の各社のデータ(配列)を用いてCORREL関数を使ってクロス集計することで、各社間の相関係数をN列からT列までで集計をしています。
ついでに、9行から下においては相関係数から100を最大とした相関度を計算するようにしています。
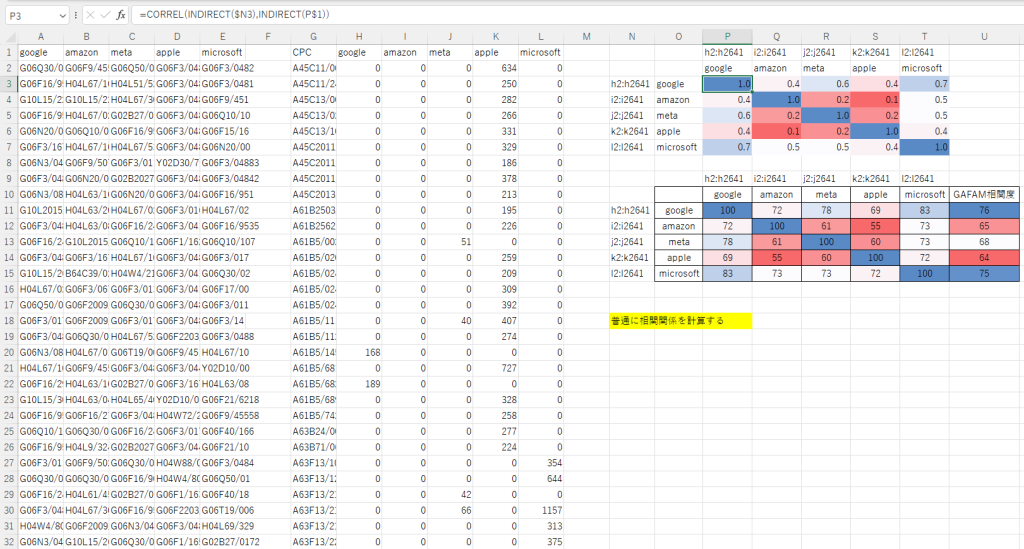
このような集計を行うことで、例えば、googleは、microsoftと出願ポートフォリオとして近い技術の出願をしている、つまり近い技術について研究開発することで技術的な強みを持っていることがわかり、ビジネスモデルが近く訴訟等のリスクが高いプレイヤー同士であるともいえます。
逆に、appleとamazonとは、出願ポートフォリオとして遠い技術について出願していることがわかります。つまり、appleとamazonとは、相対的に遠い技術について研究開発することで技術的な強みを持っていることがわかり、ビジネスモデルとしては近くないので相対的に訴訟等のリスクは低いプレイヤー同士であるともいえます。
この例ではGAFAMを対象に類似度を推定していますが、特定の出願人を基準として設定し、その出願人の出願分野において出願している他のどの出願人が当該特定の出願人の出願の分類で類似しているか確認することもできます。
以上のように、今回はCORREL関数を使った類似度の推定ツールについて紹介しました。弊所ではこのツールなど様々な特許情報分析の手法を用意しており、クライアントの要望に沿った分析手法の開発も行っています(なお、弊所では顧問契約をしていただいているクライアント様には弊所開発のツールを自由に利用して頂いています)。
また、このような分析手法に関する個別指導・セミナーや、個別の分析プロジェクトについても対応可能です。ご相談などありましたら管理人の特許事務所のページからお知らせください。
よろしくお願いします。